도입
AI 생성 음악 탐지를 다루는 논문을 읽다 보면, CNN이라는 이름이 자주 등장합니다. 오디오를 이미지처럼 생긴 2차원 표현(스펙트로그램)으로 변환하고 CNN을 적용하는 방식은, 오디오 딥페이크 탐지에서 오랫동안 기본 접근법으로 사용되어 왔습니다.
CNN은 Convolution Neural Network의 줄임말로, 한국어로는 합성곱 신경망이라고 부릅니다. 일종의 인공 신경망으로, 이미지처럼 격자 형태로 배열된 데이터를 다루는 데 특화된 구조입니다. 이미지 분류, 객체 탐지 같은 시각 관련 작업에서 널리 쓰이고, 오디오를 격자 형태로 변환하면 음향 분석에도 쓸 수 있습니다.
CNN의 핵심 아이디어는 입력 전체를 한꺼번에 보지 않고, 작은 영역씩 훑으면서 패턴을 찾는다는 것입니다. 이 “작은 영역씩 훑는 계산”이 바로 합성곱(convolution)입니다.
이 글에서는 CNN을 두 부분으로 나눠 살펴봅니다. 전반부에서는 합성곱 층이 실제로 무엇을 계산하는지, 출력 크기는 어떻게 결정되는지 알아봅니다. 후반부에서는 층을 쌓으면 무슨 일이 생기는지, 비선형성과 풀링은 무엇인지 살펴봅니다.’
1. 왜 CNN인가
신경망에 대해 조금이라도 들어본 적이 있다면, 입력과 출력을 연결하는 구조를 떠올릴 수 있습니다. 가장 단순한 형태는 입력의 모든 값이 다음 층의 모든 값과 연결되는 구조인데, 이를 완전연결층(fully connected layer)이라고 부릅니다.
문제는 이미지나 스펙트로그램처럼 크기가 큰 격자 데이터를 완전연결층에 그대로 넣으면, 연결해야 할 숫자(파라미터)가 폭발적으로 늘어난다는 점입니다. 예를 들어 크기의 컬러 이미지는 값이 약 15만 개인데, 이걸 전부 다음 층의 수천 개 뉴런과 일일이 연결하면 계산량도 많고, 학습도 어려워집니다.
CNN은 이 문제를 다른 방식으로 접근합니다. 입력 전체를 한꺼번에 연결하는 대신 작은 영역만 보는 필터를 정의하고, 그 필터를 입력 위로 이동시키면서 같은 계산을 반복합니다. 이렇게 하면 파라미터 수가 훨씬 적어지고, 동시에 “가까운 위치의 값들이 함께 의미를 가진다”는 격자 데이터의 특성을 살릴 수 있습니다.
정리하면, CNN은 격자 데이터에서 국소적인 패턴을 효율적으로 찾기 위해 설계된 구조입니다. 이제 그 핵심 계산인 합성곱이 구체적으로 무엇인지 살펴보겠습니다.
2. CNN이 보는 입력: 격자
CNN은 입력을 격자로 봅니다. 격자라는 말은 값들이 가로, 세로 좌표 위에 규칙적으로 배열되어 있다는 뜻입니다. 이미지가 대표적입니다. 가로 224칸, 세로 224칸의 격자에 각 칸마다 밝기나 색상 값이 들어 있는 구조입니다.
오디오는 원래 시간에 따른 1차원 신호입니다. 하지만 이를 스펙트로그램으로 변환하면, 가로축은 시간, 세로축은 주파수인 2차원 격자가 됩니다. 각 칸에는 해당 시간대에 해당 주파수가 얼마나 강한지를 나타내는 값이 들어갑니다.
AI 생성 음악 탐지 연구에서 특히 자주 쓰이는 것은 멜 스펙트로그램(Mel Spectrogram)입니다. 일반 스펙트로그램의 주파수 축을 사람의 청각 특성에 맞게 변환한 것으로, 사람 귀가 저주파 영역의 변화에 더 민감하다는 점을 반영합니다. 앞으로 다룰 기존의 논문들도 대부분 오디오를 멜 스펙트로그램으로 변환한 뒤 CNN에 입력하는 방식을 사용합니다.
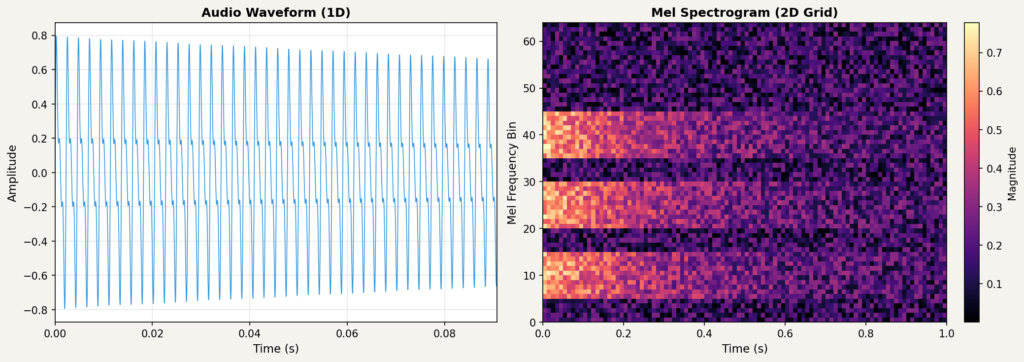
이렇게 변환하면 오디오도 이미지처럼 다룰 수 있고, CNN을 적용할 수 있습니다. AI 생성 음악 탐지에서 CNN을 쓸 수 있는 이유가 여기에 있습니다.
격자에 색상 정보처럼 여러 종류의 값이 있으면, 채널이라는 차원이 추가됩니다. 컬러 이미지는 빨강, 초록, 파랑의 3개 채널을 가집니다. 이 경우 입력은 채널 높이 너비의 3차원 구조가 됩니다. 채널이 계산에 어떤 영향을 주는지는 뒤에서 다시 다루겠습니다.
3. 합성곱이란
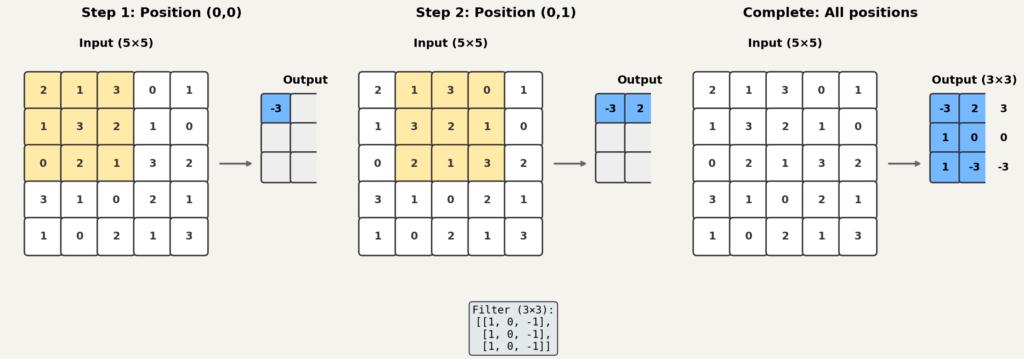
합성곱 층에는 필터(filter)라는 작은 격자가 있습니다. 커널(kernel)이라고도 부르지만, 이 글에서는 필터로 통일하겠습니다. 필터는 보통 이나 처럼 입력보다 훨씬 작은 크기입니다.
계산은 다음과 같이 진행됩니다.
- 필터를 입력 격자의 왼쪽 위 구석에 올려놓습니다.
- 필터와 겹치는 입력 영역에서, 같은 위치끼리 값을 곱합니다.
- 곱한 값들을 모두 더해서 하나의 숫자를 만듭니다.
- 이 숫자가 출력 격자의 한 칸이 됩니다.
- 필터를 오른쪽으로 한 칸 옮기고, 같은 계산을 반복합니다.
- 오른쪽 끝에 도달하면 아래로 한 줄 내려가서 다시 왼쪽부터 시작합니다.
- 입력 전체를 훑을 때까지 반복합니다.
이렇게 해서 만들어진 출력 격자를 특징맵(feature map)이라고 부릅니다. “특징”이라는 이름이 붙은 이유는, 필터가 입력에서 특정 패턴에 반응하도록 학습되기 때문입니다.
핵심을 다시 정리하면 이렇습니다. 출력의 한 칸은 입력 전체가 아니라, 필터 크기만큼의 작은 영역만 보고 만들어집니다. 이것이 CNN에서 말하는 국소(local) 연산입니다.
수식으로 정리
수식으로 살펴보면 더 정확해집니다. 입력을 , 필터를 , 출력을 라고 하겠습니다. 필터 크기가
이고, 필터가 한 칸씩 이동한다고 하면, 출력의 한 칸은 다음과 같습니다.
이 수식을 말로 풀면 이렇습니다. 입력에서 위치 를 시작점으로 영역을 잡습니다. 그 영역과 필터를 같은 위치끼리 곱하고, 전부 더한 값이 가 됩니다. 와 를 바꿔가며 이 계산을 반복하면 특징맵 전체가 완성됩니다.1
실제 구현에서는 여기에 편향(bias) 가 더해져서 형태가 됩니다. 편향은 필터당 하나씩 있고, 출력의 모든 위치에 같은 값이 더해집니다. 이 글에서는 핵심 연산에 집중하기 위해 편향을 생략했지만, 코드나 논문에서는 대부분 포함되어 있습니다.
숫자 예시로 직접 계산해보기
실제 숫자로 한 번 계산해보겠습니다.
입력의 한 부분이 다음과 같다고 가정합니다.
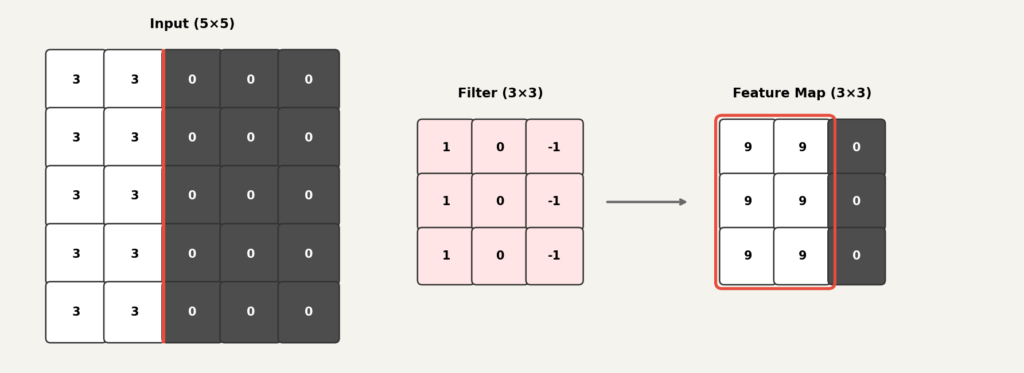
필터가 다음과 같다고 가정합니다.
이 필터는 왼쪽 열은 , 오른쪽 열은 로 되어 있습니다. 직관적으로 보면, 왼쪽이 밝고 오른쪽이 어두운 패턴(세로 경계)에 크게 반응하도록 설계된 필터입니다.
출력 한 칸을 계산해 보겠습니다. 같은 위치끼리 곱하고 더합니다.
결과는 입니다. 중요한 것은 이 값 자체가 아니라, 입력 패치의 값 배치가 바뀌면 출력도 달라진다는 점입니다. 만약 입력이 왼쪽은 밝고 오른쪽은 어두운 패턴이었다면, 이 필터는 큰 양수를 출력했을 것입니다.
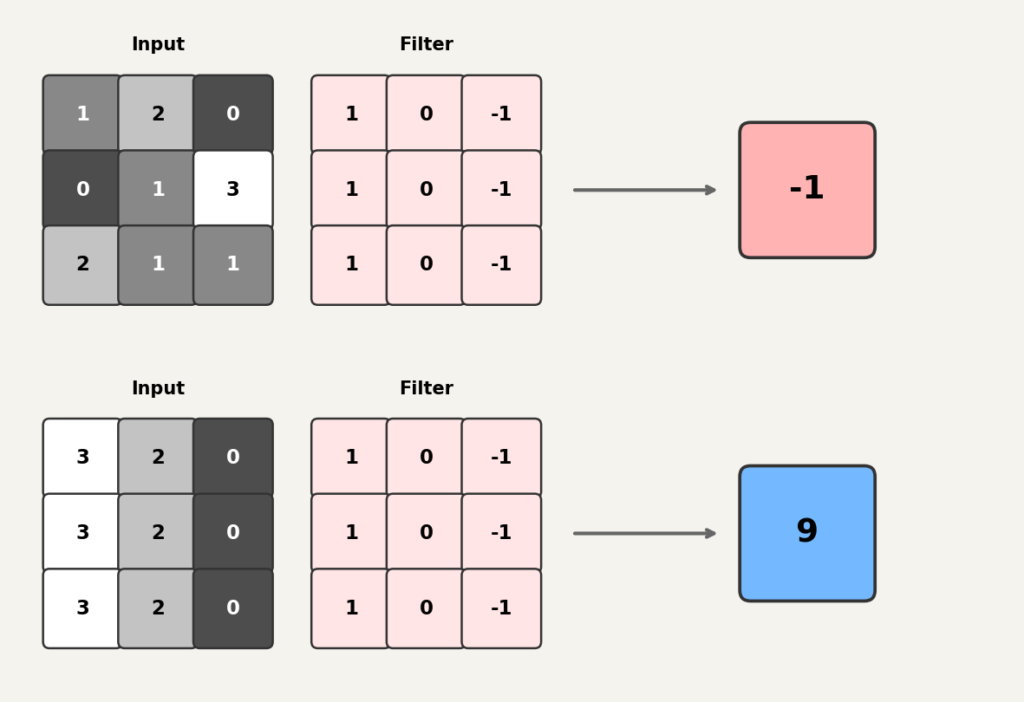
같은 필터라도 입력 패턴에 따라 출력이 달라진다.
CNN은 학습 과정에서 데이터에 맞게 필터의 값을 조정합니다. 멜 스펙트로그램에서 특정 시간-주파수 패턴을 잡아내는 것도 결국 이 원리입니다. 따라서 합성곱 층을 국소 패턴에 반응하는 계산 단위로 이해하는 것이 출발점이 됩니다.
4. 출력 크기는 어떻게 결정되는가
지금까지는 필터가 한 칸씩 이동한다고 가정했습니다. 하지만 실제로는 이동 간격을 조절하거나, 입력 가장자리에 값을 덧붙이는 경우가 많습니다. 이 두 가지 개념을 알아야 출력 크기를 계산할 수 있습니다.
스트라이드(stride): 필더가 한 번에 몇 칸씩 이동하는지를 나타냅니다. 스트라이드가 이면 한 칸씩, 이면 두 칸씩 이동합니다. 스트라이드가 크면 출력 격자가 작아집니다.
패딩(padding): 입력 가장자리에 같은 값을 덧붙여서 입력을 인위적으로 키우는 것입니다. 패딩을 넣으면 필터가 가장자리까지 충분히 훑을 수 있어서, 출력 크기가 덜 줄어들거나 유지됩니다.
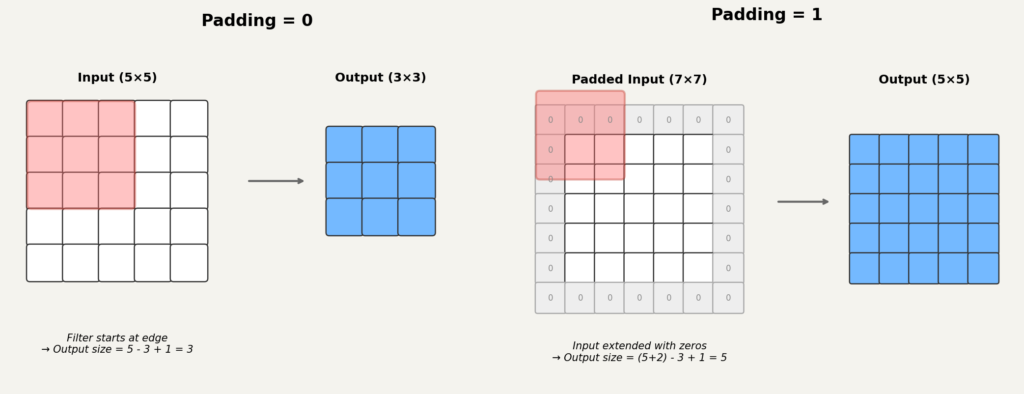
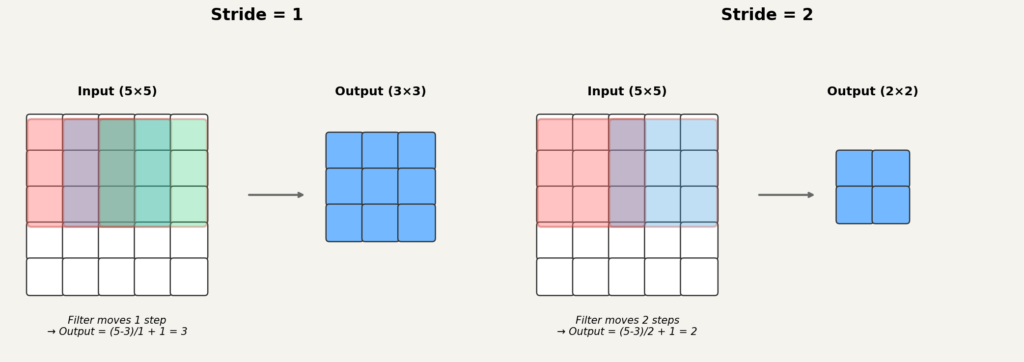
출력 크기를 구하는 공식은 다음과 같습니다. 입력 높이를 , 너비를 , 필터 크기를 , 패딩을 , 스트라이드를 라고 하면:
기호는 바닥함수로, 해당 값을 넘지 않는 가장 큰 정수를 뜻합니다. 이 공식은 인 표준 합성곱을 가정합니다.2
숫자를 대입해 보겠습니다.
예시 1: 크기 유지
입력 높이가 , 필터가 , 패딩이 , 스트라이드가 이면 다음과 같습니다.
필터에 패딩 , 스트라이드 이면 출력 크기가 입력과 같습니다. 이 조합은 실제 모델에서 아주 자주 등장합니다.
예시 2: 크기를 절반으로 줄이기
같은 조건에서 스트라이드를 2로 바꾸면 다음과 같습니다.
출력이 절반으로 줄어듭니다. 스트라이드가 크면 필터가 넓은 간격으로 이동하므로 출력이 작아집니다.
5. 채널이 있을 때는 어떻게 되는가
지금까지는 입력이 2차원(높이 너비)이라고 가정했습니다. 하지만 실제 입력은 채널을 가지는 경우가 많습니다.
컬러 이미지는 빨강, 초록, 파랑 3개 채널을 가집니다. 멜 스펙트로그램도 여러 표현을 함께 사용하면 채널이 여러 개가 될 수 있습니다. 예를 들어 기본 멜 스펙트로그램에 시간에 따른 변화량(델타 특징)을 추가하면 채널이 늘어납니다. 그리고 CNN의 중간 층에서는 이전층의 출력이 입력이 되는데, 이때 채널이 수십에서 수백 개일 수도 있습니다.
입력 형태를 채널 높이 너비, 즉 ()로 쓰겠습니다. 참고로 이 표기는 PyTorch의 관례를 따른 것입니다. TensorFlow나 일부 데이터 형식에서는 ()순서를 쓰기도 합니다.
채널이 있으면 필터도 같은 채널 수를 가집니다. 그리고 출력 한 칸을 계산할 때, 모든 채널에서 곱하고 더한 값을 다시 채널 방향으로 합칩니다.
즉, 채널이 늘어나면 합산 범위가 채널 방향으로 확장됩니다. 결과적으로 필터 하나는 모든 채널의 정보를 종합해서 출력 한 칸을 만듭니다.
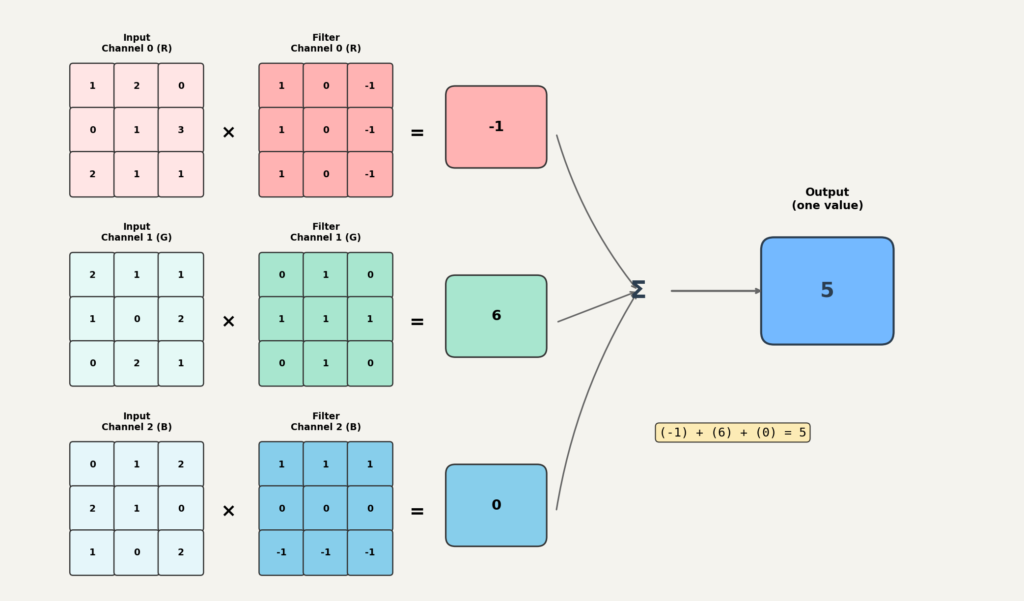
필터 개수와 출력 채널
여기서 중요한 규칙이 하나 있습니다. 필터 1개는 특징맵 1개를 만듭니다.
필터를 여러 개 사용하면, 각 필터가 하나씩 특징맵을 만들고, 이 특징맵들이 쌓여서 출력의 채널이 됩니다. 따라서 출력 채널 수는 필터 개수로 결정됩니다.
예를 들어 입력이 이고 필터 64개를 사용하면, 출력은 이 됩니다(패딩과 스트라이드에 따라 높이와 너비는 달라질 수 있습니다). 번째 차원이 필터 개수이고, 이것이 곧 출력 채널 수가 됩니다.3
중간 정리
여기까지 합성곱 한 층이 무엇을 계산하는지 살펴봤습니다. 정리하면 다음과 같습니다.
- CNN은 격자 형태의 데이터에서 국소 패턴을 효율적으로 찾기 위한 신경망이다.
- 핵심 계산인 합성곱은 작은 필터를 입력 위로 이동시키면서, 겹치는 영역의 값을 곱하고 더해 특징맵을 만드는 연산이다.
- 출력의 한 칸은 입력 전체가 아니라 필터 크기만큼의 작은 영역만 본다.
이제 이 계산을 층으로 쌓으면 무슨 일이 생기는지 알아봅니다.
6. 특징맵 다시 보기
합성곱의 출력을 특징맵(feature map)이라고 부른다고 했습니다. 이 이름이 붙은 이유를 조금 더 생각해 봅니다.
특징맵의 각 칸에는 숫자가 들어 있습니다. 이 숫자는 해당 위치의 입력 패치와 필터의 가중합(내적)에 가까운 반응값이며, 직관적으로는 ‘비슷할수록 크게 반응한다’고 이해할 수 있습니다. 다만 이는 정규화된 유사도가 아니라 가중합 값이어서, 값의 크기는 대체로 입력 스케일이나 학습 상태에 따라 달라질 수 있습니다. 일반적으로 값의 절댓값이 클수록 반응이 강합니다. 대체로 양수는 필터가 기대하는 패턴 방향과 비슷한 것이 있고, 음수는 반대 방향인 것입니다. 예를 들어 세로 경계를 찾는 필터가 있을 때, “왼쪽이 밝고 오른쪽이 어두운”경계에서는 큰 양수가, “왼쪽이 어둡고 오른쪽이 밝은”경계에서는 큰 음수가 나올 수 있습니다. 활성화 함수를 적용하면 음수 반응은 으로 제거됩니다(활성화 함수에 대해서는 7장에서 다룹니다).
따라서 특징맵은 일종의 지도입니다. “이 패턴이 입력의 어디에 있는가”를 위치별로 기록한 결과물입니다. 필터가 세로 경계를 찾도록 학습되었다면, 특징맵에서 값이 큰 위치는 입력에서 세로 경계가 있는 곳입니다.
CNN에서 필터는 여러 개 사용됩니다. 필터마다 다른 패턴을 찾고, 필터마다 특징맵이 하나씩 만들어집니다. 결과적으로 한 층의 출력은 여러 장의 특징맵이 쌓인 형태가 됩니다.
7. 비선형성: 왜 활성화 함수가 필요한가
합성곱은 곱하고 더하는 연산입니다. 수학적으로 이런 연산을 선형(linear) 연산이라고 부릅니다. 선형 연산에는 한 가지 특성이 있습니다. 선형 연산을 여러 번 연속으로 적용해도, 결과는 한 번의 선형 연산으로 표현할 수 있다는 것입니다.
이게 왜 문제일까요? 합성곱 층을 10개 쌓아도, 전체가 하나의 선형 변환과 같다면 층을 쌓는 의미가 없습니다. 복잡한 패턴을 표현하려면 층을 쌓을수록 표현력이 늘어나야 하는데, 선형 연산만으로는 그렇게 되지 않습니다.
이 문제를 해결하는 방법이 활성화 함수(activation function)입니다. 합성곱 출력에 비선형 함수를 적용하면, 층을 쌓을수록 표현할 수 있는 패턴의 복잡도가 실제로 늘어납니다.
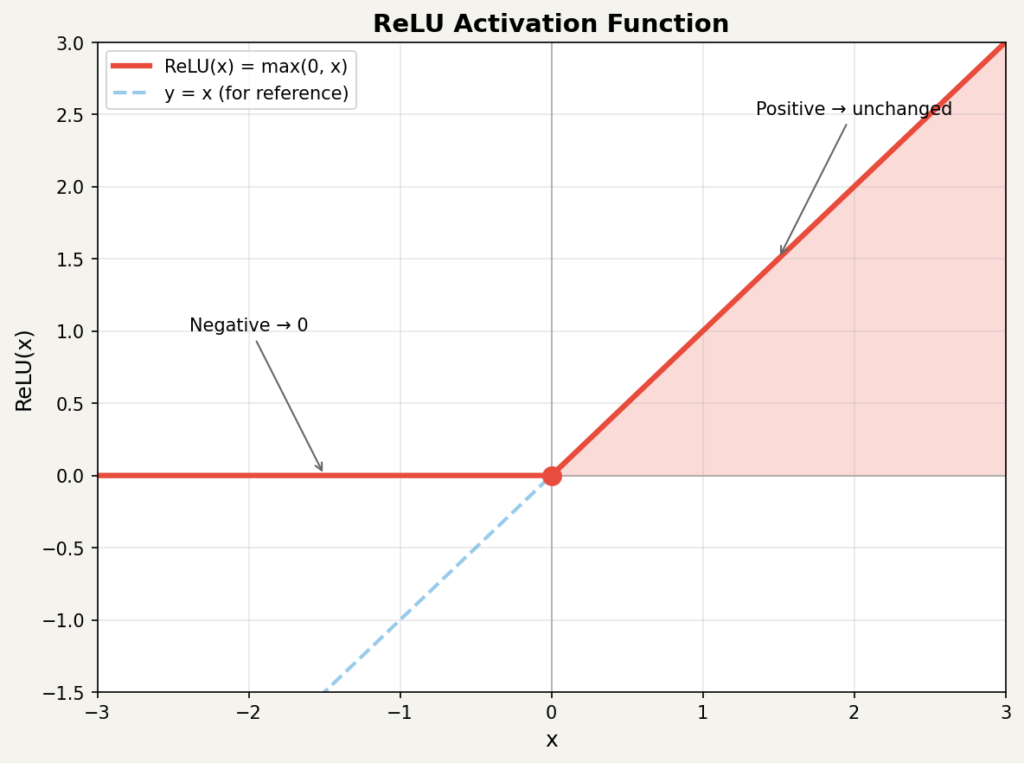
가장 널리 쓰이는 활성화 함수는 입니다. 계산은 단순합니다.
입력이 양수면 그대로 내보내고, 음수면 으로 바꿉니다. 이 간단한 연산이 비선형성을 만들어내고, 층을 깊게 쌓을 수 있게 해줍니다.
외에도 , , 같은 활성화 함수들이 있습니다. 각각 특성이 다르지만, 핵심 역할은 같습니다. 선형 연산 사이에 비선형성을 넣어서 층을 쌓는 효과를 만드는 것입니다.
8. 풀링: 해상도를 줄이면서 요약하기
풀링(pooling)은 특징맵의 크기를 줄이는 연산입니다. 작은 영역을 하나의 값으로 요약합니다.
가장 흔한 것은 최대 풀링(max pooling)입니다. 예를 들어 최대 풀링은 영역에서 가장 큰 값 하나만 남기고 나머지는 버립니다. 이렇게 하면 특징맵의 높이와 너비가 절반으로 줄어듭니다.
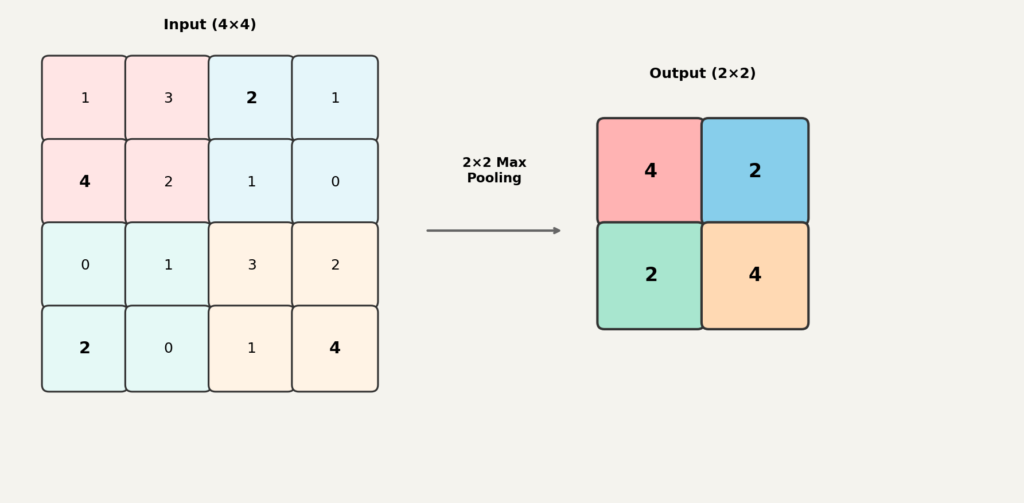
풀링을 쓰는 이유는 몇 가지가 있습니다.
첫째, 계산량을 줄입니다. 특징맵이 작아지면 다음 층에서 처리할 데이터가 줄어듭니다.
둘째, 위치 변화에 덜 민감해집니다. 패턴이 정확히 같은 위치에 없어도, 근처에 있으면 최대 풀링이 잡아냅니다. 다만 이것이 완전한 위치 불변성을 보장하는 것은 아니고, 작은 평행이동에 덜 민감해지는 정도로 이해하는 것이 정확합니다.
셋째, 다음 층이 더 넓은 범위를 보게 됩니다. 이 부분은 바로 다음에 다룹니다.
풀링 대신 스트라이드가 2 이상인 합성곱을 써서 크기를 줄이는 방법도 있습니다. 풀링은 단순히 값을 선택하지만, 스트라이드 합성곱은 학습 가능한 필터로 다운샘플링을 합니다.
9. 수용 영역: 층을 쌓으면 더 넓은 범위를 본다
수용 영역(receptive field)은 출력의 한 칸이 입력에서 참조하는 영역의 크기입니다. 앞에서 합성곱 출력 한 칸은 필터 크기만큼의 입력 영역을 본다고 했습니다. 필터라면 수용 영역은 입니다.
그런데 층을 쌓으면 상황이 달라집니다.
첫 번째 층의 출력 한 칸은 입력의 영역을 봅니다. 두 번째 층은 첫 번째 층의 출력을 입력으로 받습니다. 두 번째 층의 출력 한 칸은 첫 번째 층 출력의 영역을 봅니다. 그런데 첫 번째 층 출력의 각 칸은 이미 원본 입력의 을 보고 있었습니다.
결과적으로 두 번째 층의 출력 한 칸은 원본 입력의 영역을 간접적으로 참조합니다. 세 번째 층까지 가면 이 됩니다.
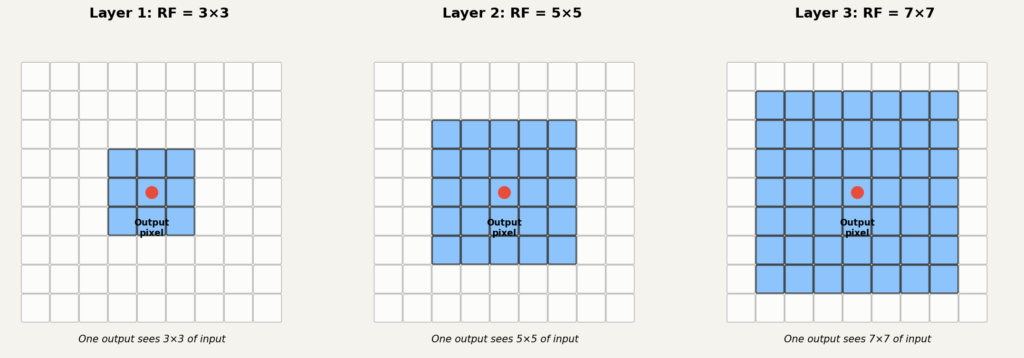
필터를 사용하고 스트라이드가 이면, 층을 하나 쌓을 때마다 수용 영역의 한 변이 씩 늘어납니다.
아래 식은 , 풀링 없이 동일한 합성곱을 번 연속 적용하는 단순한 경우를 가정합니다.
여기서 은 층의 개수, 는 필터 크기입니다. 필터로 5개 층을 쌓으면 수용 영역은 이 됩니다.
풀링이나 스트라이드 합성곱이 있으면 수용 영역은 더 빠르게 커집니다. 해상도가 줄어들 때마다, 다음 층의 한 칸이 원본 입력에서 더 넓은 영역에 대응하기 때문입니다.
10. 계층적 특징: 작은 패턴에서 큰 패턴으로
수용 영역이 커진다는 것은 단순히 “더 넓은 영역을 본다”는 의미만 있는 게 아닙니다. CNN이 복잡한 패턴을 인식하는 방식과 직결됩니다.
얕은 층은 수용 영역이 작습니다. 작은 영역만 보기 때문에, 찾을 수 있는 패턴도 단순합니다. 경계선, 질감, 색상 변화 같은 저수준 특징입니다.
깊은 층은 수용 영역이 큽니다. 넓은 영역을 보기 때문에, 앞 층들이 찾아낸 저수준 특징들의 조합을 볼 수 있습니다. 이런 조합이 더 복잡한 고수준 특징이 됩니다.
이미지에서 예를 들면, 얕은 층은 윤곽선을 찾고, 중간 층은 윤곽선들의 조합으로 눈이나 코 같은 부분을 찾고, 깊은 층은 그런 부분들의 배치로 얼굴 전체를 인식합니다.
멜 스펙트로그램에서도 비슷한 일이 일어납니다. 얕은 층은 특정 주파수 대역의 에너지 변화나 짧은 시간 패턴을 찾습니다. 깊은 층은 이런 패턴들의 조합으로 음색이나 리듬 같은 더 추상적인 특징을 찾습니다.

마무리
CNN이 입력을 처리하는 흐름을 정리하면 다음과 같습니다.
- 격자 입력: 이미지나 멜 스펙트로그램 같은 2차원 격자 데이터가 들어옴
- 합성곱: 작은 필터로 국소 패턴을 찾아 특징맵 생성
- 활성화 함수: 등으로 비선형성 부여
- 풀링: 특징맵 크기를 줄이며 정보 요약
- 층 반복: 2~4를 반복하며 수용 영역 확대, 계층적 특징 학습
이 과정을 통해 얕은 층은 경계선 같은 단순한 패턴을, 깊은 층은 복잡한 고수준 패턴을 학습합니다. 실제 모델에서는 여기에 정규화(), 규제(), 분류기(전역 평균 풀링, 완전연결층 등)가 결합되는 경우가 많습니다. 멜 스펙트로그램으로 변환된 오디오에 CNN을 적용하면, 시간-주파수 평면에서 저수준 음향 패턴부터 고수준의 음악적 특징까지 계층적으로 추출할 수 있습니다. 인간 음악과 AI 생성 음악의 차이가 이런 계층적 특징에서 포착될 가능성이 있기 때문에, CNN이 AI 생성 음악을 포함한 오디오 딥페이크 탐지에 활용되어 왔습니다.
참고문헌
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press. (CNN 전반, 합성곱, 비선형성, 풀링)
LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-Based Learning Applied to Document Recognition. Proceedings of the IEEE, 86(11), 2278–2324. (CNN 기본 구조)
Nair, V. & Hinton, G. E. (2010). Rectified Linear Units Improve Restricted Boltzmann Machines. Proceedings of the 27th International Conference on Machine Learning (ICML-10), 807–814. (ReLU 활성화 함수)
Hershey, S. et al. (2017). CNN Architectures for Large-Scale Audio Classification. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 131–135. (오디오 CNN) (preprint: arXiv:1609.09430)
Dumoulin, V. & Visin, F. (2016). A guide to convolution arithmetic for deep learning. arXiv:1603.07285. (출력 크기 공식, 패딩, 스트라이드)
- 엄밀한 신호처리에서 은 필터를 뒤집어서 계산하는 연산입니다. 반면 본문의 수식처럼 필터를 뒤집지 않고 그대로 쓰는 연산은 이라고 부릅니다. 딥러닝 프레임워크들은 대부분 을 구현하면서 이라고 부릅니다. 필터 값은 학습으로 결정되기 때문에, 뒤집든 안 뒤집든 결과적으로 같은 패턴을 찾을 수 있습니다. 이 글에서도 관례를 따라 이 연산을 합성곱이라고 부릅니다. ↩︎
- (팽창)은 필터 원소 사이에 빈 칸을 삽입하는 기법입니다. 기본값 은 간격이 없는 일반 합성곱입니다. 이면 필터 원소 사이에 1칸씩 간격이 생겨서, 필터가 영역을 커버하게 됩니다. 필터 크기(가중치 수)는 그대로이면서 수용 영역만 넓어지는 효과가 있습니다. ↩︎
- 에서 가중치 텐서는
(out_channels, in_channels/groups, kH, kW)형태입니다. 는 입력 채널을 여러 묶음으로 나눠 각각 독립적으로 합성곱하는 옵션이며, 기본값은 입니다. 기본 설정() 에서는(out_channels, in_channels, kH, kW)로 이해해도 됩니다. 첫 번째 차원이 필터 개수이고, 이것이 곧 출력 채널 수가 됩니다. ↩︎